
在深度学习,特别是对比学习(Contrastive Learning)和度量学习(Metric Learning)的领域中,我们经常从直觉出发设计损失函数。一个最朴素的直觉是:对于特征空间中的样本,我们希望属于同一类别的样本(正样本对)尽可能接近,而不同类别的样本(负样本对)尽可能远离。在几何上,这通常被翻译为:正样本的余弦相似度(Cosine Similarity)应接近 $1$,而负样本的余弦相似度应接近 $-1$。
这种直觉在二维或三维空间中是完全成立的。然而,当我们进入高维空间($d=128, 512, 768$ 甚至更高)时,几何规则发生了剧变。本文将深入探讨这一现象,揭示为何在高维空间中将负样本推向 $-1$ 实际上是一个严重的几何误区,并引出“正交性原理”的重要性。
一、 这里的“直觉”陷阱
让我们先回顾一下标准的对比学习目标。给定一个锚点样本 $x$(Anchor),我们希望拉近它与正样本 $x^+$ 的距离,同时推远它与负样本 $x^-$ 的距离。在归一化的超球面上,距离通常由余弦相似度 $\cos(x, y)$ 来衡量。
用户设定的几何目标通常是:同类接近 $1$,不同类接近 $-1$。
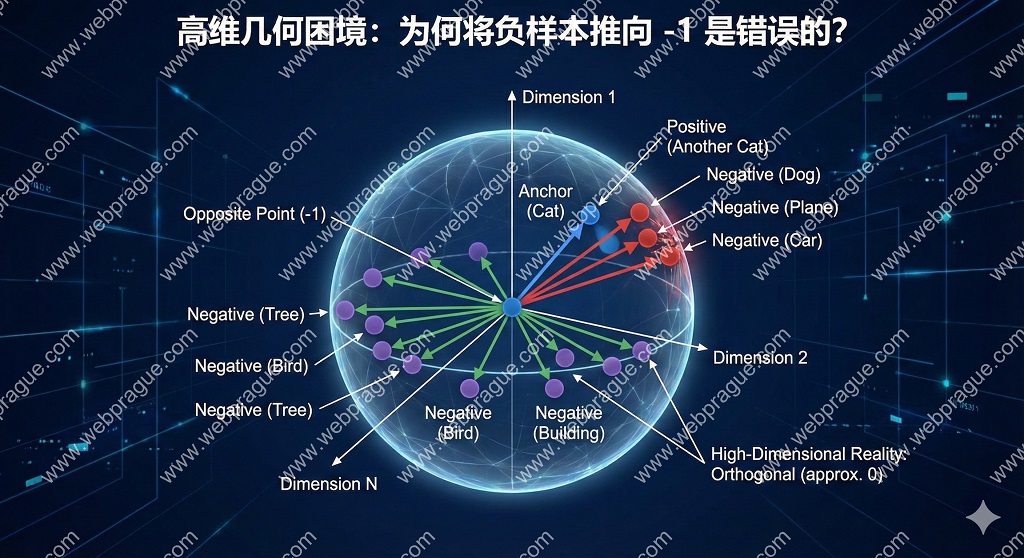
前半部分(正样本 $\to 1$)是绝对合理的。如果两个向量完全重合,意味着它们携带的语义信息高度一致,这是我们所追求的。但是,后半部分(负样本 $\to -1$)却隐藏着巨大的隐患。在低维空间,比如一个二维的圆环上,让两个点“最远”,确实意味着它们应该位于圆的对径点(Antipodal points),即夹角为 $180^\circ$,余弦值为 $-1$。这是我们在欧几里得几何直觉下得出的自然结论。
然而,深度学习模型处理的特征向量往往位于极高维度的超球体表面。在这种环境下,空间结构不再符合我们的低维直觉。
二、 维度的诅咒与测度集中现象
高维几何中有一个核心概念叫做测度集中(Concentration of Measure)。简单来说,随着维度的增加,超球体的体积分布会出现反直觉的现象。我们可以通过数学推导来理解这一点。
假设我们在 $d$ 维单位超球面上随机采样两个向量 $x$ 和 $y$。我们可以研究它们之间夹角 $\theta$ 的分布,或者更直接地,研究它们点积(即余弦相似度,因为是单位向量)的分布。在高维空间中,两个随机向量的点积分布高度集中在 $0$ 附近。
具体来说,对于任意给定的一个极点(Anchor),球面上绝大部分的面积都集中在该点对应的“赤道”附近。也就是说,随机选取的两个向量,它们大概率是正交(Orthogonal)的。
我们可以用一个近似公式来描述这种集中效应。如果 $x$ 和 $y$ 是 $d$ 维球面上的随机向量,那么它们的点积 $\langle x, y \rangle$ 的期望是 $0$,方差约为 $1/d$。这意味着,当 $d$ 很大时,绝大多数点对的余弦相似度都落在 $[-\epsilon, \epsilon]$ 这样一个极小的区间内,其中 $\epsilon \propto 1/\sqrt{d}$。
三、 为什么推向 -1 是错误的?
理解了“赤道集中”原理后,我们就能明白为何将负样本推向 $-1$ 是有问题的。
1. 空间的稀缺性:
在超球面上,与锚点 $x$ 夹角为 $180^\circ$(即余弦为 $-1$)的点只有一个,那就是它的对径点 $-x$。即使我们放宽条件,考虑余弦值接近 $-1$ 的区域(即“南极”附近的区域),这个区域的表面积在高维空间中也是微乎其微的。相比之下,与锚点正交(余弦接近 $0$)的区域——即“赤道带”——占据了超球面上绝大多数的面积。
2. 优化难度的剧增:
如果我们强行要求所有负样本都趋向于 $-1$,实际上是在强迫模型将成千上万个不同的负样本挤压到超球面上一个极小的“南极点”区域。这在几何上是非常拥挤且困难的。这就好比要求全世界的人都挤站在南极点的一块瓷砖上,而废弃了广阔的赤道地区。
3. 语义表达的限制:
负样本之间本身也是有语义差异的。如果我们将所有负样本都推向同一个点($-x$),那么负样本之间的距离就会被迫变为 $0$。这意味着模型失去了区分不同负样本的能力,导致特征空间的坍缩。
四、 正交性原理:更好的几何目标
基于上述分析,高维几何给我们的启示是:对于负样本,我们不应该要求它们与锚点“相反”($-1$),而应该要求它们与锚点“无关”($0$)。
这就是正交性原理。在 $d$ 维空间中,我们可以找到 $d$ 个相互正交的向量。当 $d$ 很大时(例如 $d=512$),我们可以轻松地在赤道附近容纳海量的负样本,而不需要它们互相重叠。让负样本分布在赤道附近($\cos \theta \approx 0$),既符合高维空间的自然分布规律,又给了模型足够的自由度来保持负样本之间的多样性。
这也是为什么现代的对比学习损失函数(如 InfoNCE)中,虽然分母项确实希望最小化正样本相似度并最大化负样本相似度,但在实际收敛状态下,负样本的相似度通常维持在 $0$ 附近(或 $1/\sqrt{d}$ 量级),而不是 $-1$。如果我们在设计 Loss 时显式地加上 $\left\| \cos(x, x^-) - (-1) \right\|^2$ 这样的约束,往往会导致模型性能下降。
五、 总结与展望
高维空间是违反直觉的。从“负样本 $\to -1$”到“负样本 $\to 0$”的认知转变,体现了从欧几里得低维直觉向高维统计几何思维的跃迁。在设计深度学习算法时,我们需要时刻警惕“维度的诅咒”,利用高维空间的特性(如巨大的赤道面积)来优化特征分布。
当我们再次面对模型训练中的几何目标时,不妨记住:在高维的宇宙里,最远的距离不是南极与北极,而是被挤压在一点的窒息;最宽广的自由,是存在于彼此正交的独立之中。